Beautiful Soup库 安装和使用
beautifulsoup能够解析HTMl和XML格式文档,是解析、遍历、维护“标签树”的功能库。
安装
pip install beautifulsoup4
使用
1 | from bs4 import BeautifulSoup |
Beautiful Soup库解析器
| 解析器 | 使用方法 | 条件 |
|---|---|---|
| bs4的HTML解析器 | BeautifulSoup(mk, ‘html.parser’) | 安装bs4库 |
| lxml的HTML解析器 | BeautifulSoup(mk, ‘lxml’) | pip install lxml |
| lxml的xml解析器 | BeautifulSoup(mk, ‘xml’) | pip install lxml |
| html5lib的解析器 | BeautifulSoup(mk, “html5lib”) | pip install html5lib |
BeautifulSoup类的基本元素
| 基本元素 | 说明 |
|---|---|
| Tag | 标签,最基本的信息组织单元,分别用 <> he </> 标明开头和结尾 |
| Name | 标签的名字,<p>...</p>的名字是’p’, 格式:<tag>.name |
| Attributes | 标签的属性,字典形式组织,格式:<tag>.attrs |
| NavigableString | 标签内非属性字符串,<>...</>中的字符串,格式:<tag>.string |
| Comment | 标签内字符串的注释部分,一种特殊的Comment类型 |
1 | from bs4 import BeautifulSoup |
标签树的下行遍历
| 属性 | 说明 |
|---|---|
| .contents | 字节点的列表,将 |
| .children | 字节点的迭代类型,与.contents类似,用于循环遍历儿子节点 |
| .descendants | 子孙节点的迭代类型,包含所有子孙节点,用于循环遍历 |
1 | print soup.head.contents # [<title>This is a python demo page</title>] |
标签树的上行遍历
| 属性 | 说明 |
|---|---|
| .parent | 节点的父亲标签 |
| .parents | 节点先辈标签的迭代类型,用于循环遍历先辈节点 |
1 | print soup.title.parent # <head><title>This is a python demo page</title></head> |
标签树的平行遍历
平行遍历发生在同一个父亲节点下的各节点间。
| 属性 | 说明 |
|---|---|
| .next_sibling | 返回按照HTML文本顺序的下一个平行节点标签 |
| .previous_sibling | 返回按照HTML文本顺序的上一个平行节点标签 |
| .next_siblings | 迭代类型,返回按照HTML文本顺序的后续所有平行节点标签 |
| .previous_siblings | 迭代类型,返回按照HTML文本顺序的前续所有平行节点标签 |
1 | print soup.a.next_sibling # ' and ' |
prettify()方法
prettify()方法可以使HTMl内容更加友好的显示。该方法为HTMl的标签添加换行符,也可以对每个标签进行处理。
注意: BeautifulSoup库将读入的HTML文件或字符串都转换成uhf-8编码。
信息标记
- 标记后的信息可形成信息组织结构,增加了信息的维度。
- 标记后的信息可用于通信、存储或展示。
- 标记的结构与信息一样具有重要价值。
- 标记后的信息更有利于程序理解和运用。
例如HTML的信息标记:
HTML通过预定义的<>...</>标签形式组织不同类型的信息。
信息标记的种类:
- XML
- JSON:有类型的键值对
"key": "value" - YAML:无类型的键值对
key:value,缩进表示所属关系;-表达并列关系;|表达整块数据;#表达注释
1 | name : |
三种信息标记种类的比较:
- XML 最早的通用信息标记语言,可扩展性好,但繁琐。Internet信息交互和传递。
- JSON 信息有类型,适合程序处理(js),较XML简洁。移动应用云端和节点的信息通讯,无注释。
- YAML 信息无类型,文本信息比例最高,可读性好。各类系统的配置文件,有注释易读。
信息提取的一般方法
1、完整解析信息的标记形式,再提取关键信息。需要标记解析器
优点:信息解析准确
缺点:提取过程繁琐,速度慢
2、无视标记形式,直接搜索关键信息。对信息文本查找函数即可
优点:提取过程简洁,速度较快
缺点:提取结果准确性和信息内容相关
在使用的时候,最好是两者融合:结合形式解析与搜索方法,提取关键信息。需要标记解析器及文本查找函数。
1 | from bs4 import BeautifulSoup |
基于bs4库的HTML内容查找方法
在BeautifulSoup变量中查找里面的信息。
<>.find_all(name, attrs, recursive, string, **kwargs) 返回一个列表类型,存储查找的结果
- name:对标签名称的检索字符串,可以为字符串、列表、正则表达式
1 | print soup.find_all('a') # [<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a>, <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>] |
- attrs:对标签属性值的检索字符串,可标注属性检索。
1 | soup.find_all('p', 'course') |
- recursive:是否对子孙全部检索,默认True
1 | soup.find_all('a') |
- string:
<>...</>中字符串区域的检索字符串
1 | soup.find_all(string="Basic Python") |
<tag>(..) 等价于 <tag>.find_all(..)
find_all的七种扩展方法
| 方法 | 说明 |
|---|---|
<>.find |
搜索且返回一个结果,字符串类型,同find_all()参数 |
<>.find_parents() |
在先辈节点中搜索,返回列表类型,同find_all()参数 |
<>.find_parent() |
在先辈节点中搜索,返回字符串类型,同find_all()参数 |
<>.find_next_siblings() |
在后续平行节点中搜索,返回列表类型,同find_all()参数 |
<>.find_next_sibling() |
在后续平行节点中搜索,返回字符串类型,同find_all()参数 |
<>.find_previous_siblings() |
在前序平行节点中搜索,返回列表类型,同find_all()参数 |
<>.find_previous_siblings() |
在前序平行节点中搜索,字符串类型,同find_all()参数 |
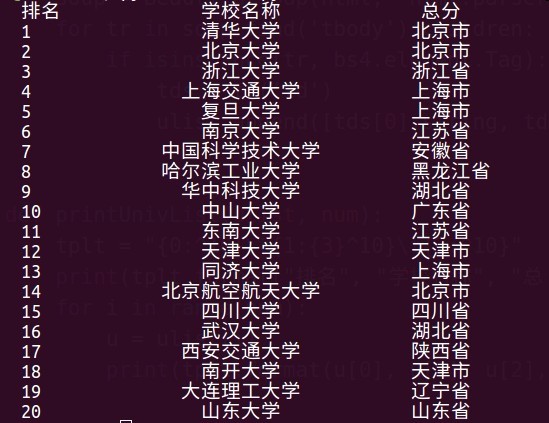
中国大学排名定向爬虫实战
功能描述
- 输入:大学排名url链接
- 输出:大学排名信息的屏幕输出
- 技术路线:requests+bs4
- 定向爬虫:仅对输入的URL进行爬取,不扩展爬取
1 | # -*- coding: utf-8 -*- |